




Java 기반의 서버 애플리케이션은 운영 중에 아래와 같은 메세지와 함께 장애로 이어지는 결과가 일어나곤 합니다.
Java.lang.OutOfMemoryError: Java heap space
Bash
복사
Java.lang.OutOfMemoryError: Permgen space
Bash
복사
Java 기반의 애플리케이션의 메모리는 운영체제의 JVM에서 관리하기 때문에 최악의 효율이 발생한다면 Full GC로 인해 애플리케이션이 멈추는 Stop The World 현상에서 자유로울 수 없습니다.
이렇게 우리가 운영하고 있는 서비스는 하루에도 몇 번씩 GC가 발생하고 있고, 이런 상황에서 시스템 이슈로 인한 장애 알람을 받지 않아도 우리의 생각과는 다르게 사용자에게 503(Service Unavailable) 오류가 반환되고 있을지도 모르는 일입니다.
이 글에서는 Java 시스템을 운영 중 문제가 발생할 때 기본적으로 알아두어야할 내용을 다룹니다.
프로세스와 쓰레드
웹 애플리케이션은 일반적인 경우에는 처리량을 극대화하는 것보다는 많은 사용자에게 지연 시간을 최대한 줄이면서 안정적인 서비스를 제공하는 것이 중요하다.
좋은 시스템은 이와 같이 어떻게 서비스의 특징에 맞게 컴퓨터의 자원을 효율적으로 사용하는지에 대한 고민으로 시작된다.
우리가 알다시피 운영체제는 컴퓨터의 자원을 여러 프로세스가 효율적으로 사용할 수 있도록 도와준다. 예를 들면 웹 애플리케이션을 효율적으로 운영하기 위해 Apache, Tomcat를 사용한다고 가정해보자. Apache, Tomcat 역시 운영체제로부터 프로세스를 할당받아 컴퓨터의 자원을 사용하고 애플리케이션 내부에서는 프로세스의 자원을 활용해 쓰레드를 생성한다.
이것은 운영체제에서 서버 애플리케이션을 효율적으로 운영하기위해서는 먼저 Apache, Tomcat의 특성을 파악해야하는 것을 의미한다.
Apache는 정적 리소스를 효율적으로 제공한다
웹 애플리케이션을 구성하면서 이미지나 HTML 페이지와 같은 정적(static) 리소스를 Tomcat과 같은 WAS에서 모두 제공할 수도 있지만 정적 리소스는 Apache를 통해 관리하는 것이 유리하다.
•
Tomcat은 정적 페이지에 대해 Apache만큼 빠르지 못하다.
•
Tomcat은 Apache 만큼 Reverse Proxy 서버를 구성하기 위한 다양한 설정을 제공하지 않는다.
그럼 Apache를 통해 얻을 수 있는 유리한 점들을 더 살펴보도록 하자.
Apache와 프로세스
웹서버 성능에 가장 큰 영향을 주는 것은 메모리다. 스왑은 요청당 지연시간을 늘리기 때문에 웹서버는 스왑을 하면 안된다. 지연시간이 늘어나면 사용자는 정지하고 다시 접속하면 접차 부하가 계속 증가한다. Apache에서는 MaxClients 지시어를 조절하여 웹서버가 스왑을 할 정도로 많은 자식을 만들지않도록 해야 한다.
MaxClients의 이상적인 값을 찾는 방법은 간단하다, 리눅스의 top과 같은 도구에서 프로세스 목록을 보고 아파치 프로세스의 평균 메모리 사용량을 알아낸 후 전체 사용가능한 메모리에서 다른 프로세스들이 사용할 공간을 뺀 값에서 나눈다.
모든 설정값은 이와 같이 이론적으로 판단할 수 있지만 정답이라는 것은 없다. 최적화를 위해서는 꼭 성능테스트를 동반하여야 한다.
나머지는 평범하다. 충분히 빠른 CPU, 충분히 빠른 네트워크 카드, 충분히 빠른 디스크, 여기서 충분히 빠른이란 의미는 실험을 통해 결정해야 한다. 운영체제는 보통 각자 알아서 선택할 일이지만 일반적으로 유용하다고 판명된 몇가지 지침은 아래와 같다.
•
선택한 운영체제의 최신 안정 버전과 패치를 실행한다. 많은 운영체제 제작사는 최근 TCP 스택과 쓰레드 라이브러리에 많은 속도향상을 했다.
•
클라이언트와 서버에 쓰이는 CPU와 메모리 모두 성능이 과거와는 비교할 수 없을 정도로 매우 좋아졌다.
Keep-Alive를 사용한다면 자식들은 이미 열린 연결에서 추가 요청을 기다리며 아무것도 하지않기 때문에 계속 바쁘다. KeepAliveTimeout의 기본값 15초는 이런 현상을 최소화한다. 네트워크 대역폭과 서버 자원 간의 균형이 맞게 설정한다. 연결유지의 대부분의 이점이 사라지기때문에 어떤 경우에도 이 값을 60 초 이상으로 올리지 마라.
Keep-Alive
앞서 말한 Keep-Alive를 활용하는 예를 설명하자면 HTTPS를 들 수 있다.
HTTPS의 암호화 비용
웹 애플리케이션에서 클라이언트 서버간에 주고 받는 메세지를 보호하기 위해서는 암호화 과정이 필요하다. HTTP는 외부의 공격이나 스니핑에 매우 취약한 프로토콜이기 때문이다. 암호화는 위해서는 HTTP에 TLS 레이어를 입힌 HTTPS 프로토콜을 일반적으로 사용한다.
하지만 암호화를 위해서는 클라이언트와 서버간에 암호화 알고리즘과 키를 교환하는 handshake 과정이 필요하다. 거기다 HTTPS 인증서를 검증하는 Online Certificate Status Protocol를 통해 인증서 및 인증 기관이 유효한지도 판단한다.

https://tech.ssut.me/2017/05/07/https-is-faster-than-http/
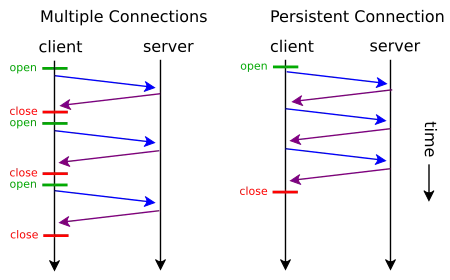
매 요청마다 이런 handshake를 진행하고 비용이 큰 RSA 알고리즘을 통해 통신을 한다면 서버와 클라이언트 모두 큰 부하가 발생할 수 밖에 없다. 다행인 점은 위 과정이 모두 마친 후의 실제 데이터 통신은 대칭키로 암호화하여 진행된다는 점이다, 여기에 Keep-Alive를 이용하면 세션이 유지될테니 암호화 비용은 줄어 들게 된다.
예) httpd.conf 에서의 Keep-Alive 설정
# KeepAlive: Whether or not to allow persistent connections (more than
# one request per connection). Set to "Off" to deactivate.
KeepAlive On
# MaxKeepAliveRequests: The maximum number of requests to allow
# during a persistent connection. Set to 0 to allow an unlimited amount.
# We recommend you leave this number high, for maximum performance.
MaxKeepAliveRequests 100
# KeepAliveTimeout: Number of seconds to wait for the next request from the
# same client on the same connection.
KeepAliveTimeout 15
Plain Text
복사
CPU와 메모리 모두 성능이 과거와는 비교할 수 없을 정도로 매우 좋아졌다
HTTPS 암호화에 쓰이는 TLS는 크게 변한 것이 없는데 반해, 클라이언트와 서버에 쓰이는 CPU와 메모리 모두 성능이 과거와는 비교할 수 없을 정도로 매우 좋아졌다. HTTPS가 HTTP보다 느리다는 논쟁은 앞으로 무의미할 것으로 보인다.
Tomcat 인스턴스의 구성
웹 애플리케이션은 스케일-업보다는 스케일-아웃하기 적합한 구조적인 특성을 가지고 있어 장비의 성능에 따라 한 대의 물리적인 장비에 한 개의 Apache 서버와 여러 개의 Tomcat 인스턴스를 구성하는 것이 일반적이였다.

주로 읽기 전용인 환경에 있어서 처리 능력 향상과 가용성의 증대라는 이점도 있다. 이는 하나의 서버가 장애를 일으켜도 다른 서버로 즉시 처리를 할 수 있는 로드 밸런싱을 의미한다.
스케일 아웃은 개개의 처리는 비교적 단순하지만 다수의 처리를 동시 병행적으로 실시하지 않으면 안 되는 경우에 적합한데 갱신 데이터의 정합성 유지에 대한 요건이 별로 어렵지 않은 경우에 적절하다
Tomcat 인스턴스 설정하기
인스턴스별 배포경로 및 로그파일 저장경로
$ mkdir -p /home/jungminhyuck/deploy/application
$ mkdir -p /home/jungminhyuck/logs/application
Bash
복사
/scripts/application-tomcat-configurations.xml
<?xml version='1.0' encoding='utf-8'?>
<Server port="8119" shutdown="SHUTDOWN">
<Listener className="org.apache.catalina.core.AprLifecycleListener" SSLEngine="off" />
<Listener className="org.apache.catalina.core.JasperListener" />
<Listener className="org.apache.catalina.core.JreMemoryLeakPreventionListener" />
<Service name="application">
<Connector port="8219" protocol="HTTP/1.1" redirectPort="8419" enableLookups="false" connectionTimeout="5000" maxThreads="5" />
<Connector port="8019" protocol="AJP/1.3" redirectPort="8319" URIEncoding="UTF-8" enableLookups="false" connectionTimeout="5000" maxThreads="2048" />
<Engine name="Catalina" defaultHost="localhost">
<Host name="localhost" appBase="webapps" unpackWARs="false" autoDeploy="false" xmlValidation="false" xmlNamespaceAware="false">
<Context docBase="/home1/jungminhyuck/deploy/application/" path="" reloadable="false" />
</Host>
</Engine>
</Service>
</Server>
XML
복사
/scripts/start-up-tomcat.sh
#!/usr/bin/env bash
XML="/home1/jungminhyuck/scripts/application-tomcat-configurations.xml"
export LC_ALL="en_US.utf8"
export LANG="en_US.utf8"
export JAVA_HOME="/home1/jungminhyuck/apps/jdk"
export CATALINA_HOME="/home1/jungminhyuck/apps/tomcat"
export CATALINA_BASE="/home1/jungminhyuck/apps/tomcat"
export CATALINA_TMPDIR="/home1/jungminhyuck/apps/tomcat/temp"
export CLASSPATH="/home1/jungminhyuck/apps/tomcat/bin/bootstrap.jar"
export CATALINA_LOG="/home1/jungminhyuck/logs/application/catalina.log"
export CATALINA_OUT="/home1/jungminhyuck/logs/application/catalina.log"
${CATALINA_BASE}/bin/startup.sh -config ${XML}
Bash
복사
CATALINA_BASE/bin/setenv.sh
export CATALINA_OPTS="$CATALINA_OPTS -Djava.awt.headless=true -server"
export CATALINA_OPTS="$CATALINA_OPTS -Xmx2048m –Xms2048m"
export CATALINA_OPTS="$CATALINA_OPTS -XX:NewSize=768m -XX:MaxNewSize=768m"
export CATALINA_OPTS="$CATALINA_OPTS -XX:PermSize=128m -XX:MaxPermSize=256m"
export CATALINA_OPTS="$CATALINA_OPTS -XX:+DisableExplicitGC -XX:ParallelGCThreads=2 -XX:-UseConcMarkSweepGC"
# Check for application specific parameters at startup
if [ -r "$CATALINA_BASE/bin/appenv.sh" ]; then
. "$CATALINA_BASE/bin/appenv.sh"
fi
Bash
복사
CATALINA_BASE/bin/appenv.sh
export CATALINA_OPTS="$CATALINA_OPTS -Dspring.profiles.active=dev"
Bash
복사
Tomcat의 애플리케이션의 maxThread는 어떤 기준으로 정의해야 하나?
maxThread는 Tomcat이 요청을 처리하기 위해 만들어내는 최대 Thread 개수를 의미한다. Tomcat과 같은 WAS는 설정해야 하는 값이 굉장히 많지만 그 중 가장 성능에 많은 영향을 주는 부분은 maxThread와 같이 Thread Pool에 직접적으로 연관된 설정일 것이다.
Thread Pool에 대한 설정은 메모리를 얼마나 할당할 것인가와 관련이 있기 때문에 Thread를 수를 많이 사용할 수록 메모리를 많이 점유하게 된다. 그렇다고 반대로 메모리를 위해 적게 지정한다면, 서버에서는 많은 요청을 처리하지 못하고 대기하는 상황이 생길수 있다.
웹 애플리케이션은 외부의 어떤 시스템과 연관되어 있나?
Tomcat의 maxThread 개수를 위해 고려할 점은 웹 애플리케이션과 연관되는 시스템도 고려할 필요가 있다. 예를 들면 실제 운영 중인 서비스에서 DB 커넥션값이 200에 가까운 수치가 설정되어 있어 문제가 발생된 경우를 보았다. 무엇보다 WAS의 maxThread의 개수는 DB 커넥션 풀의 개수에 비해 적게 설정 되어 있었는데 이는 효율적이지 못하다.
그 이유는 애플리케이션에 대한 모든 요청이 DB에 접근하는 것은 아니기 때문이다. WAS의 maxThread는 DB 커넥션 수보다 여유있게 설정하는 것이 좋다.
전환하기
지금까지의 과정을 통해 우리는 다수의 Tomcat 인스턴스를 운영하기 위한 준비를 마쳤다. 하지만 앞으로 생각해보아야 할 문제가 더욱 중요하다.

정말로 한 Box에서 다수의 Tomcat 인스턴스를 구성하는 것이 효율적일까?
우리는 지금까지 다수의 Tomcat 인스턴스를 통해 컴퓨터의 자원을 효율적으로 사용하고 가용성의 측면에서 이득을 본다고 했지만 안정적인 시스템을 위한 설계는 컴퓨터의 자원과 운영체제에 따라 언제든지 달라질 수 있다.
이보다는 다수의 장비를 운용하면서 한 Box에서 하나의 인스턴스를 운영하는 것이 대게 성능이 좋은 경우가 많은데 이는 운영체제에서 CPU의 자원을 각 프로세스에 Scheduling 정책에 따라서 할당하기 때문이다.
거기다 Tomcat의 인스턴스를 다수를 운영할 때에는 한 장비에서 수용할 수 있는 maxThread 설정을 분산해야하는 등 고려해야할 일이 많아지는 것도 단점이다.
덧붙히면 이 이슈는 마이크로 서비스 아키텍쳐에서는 논쟁 거리가 될만하다. 지난 몇 년동안 많은 개발자들이 거대한 시스템을 작은 마이크로 단위로 옮기는 노력을 해왔기 때문이다.
거기다 JVM과 컴퓨터의 성능은 점점 향상되고 있다는 것이다. G1 GC가 안정적으로 작동하는 지금은 한 장비에서 4GB 이하로 자원을 나누어 다수의 Tomcat 인스턴스를 운영하는 것은 재고할만 하다.
http://openjdk.java.net/jeps/156
물론 정답이라는 것은 없으며 최적화를 위해서는 꼭 성능테스트를 동반하여야 한다.
컴퓨터 자원과 운영체제에 따라 달라지는 GC 성능
Tomcat의 인스턴스 개수를 정하여 효율적으로 컴퓨터의 자원을 활용하기 위해서는 CPU의 코어의 개수, 운영체제가 32bit인지 64bit인지, JVM에서는 어떤 Garbage Collector를 사용하는지에 따라 달라질 수 있기 때문에 단순하게 접근하기는 힘들다고 볼 수 있다.
CPU 코어의 수
보통 하나의 인스턴스를 운용하는데 1개 정도의 CPU를 사용하는게 최적화된 환경이다. 예를 들면 2CPU 머신의 경우 2개의 Tomcat 인스턴스가 적정하다. CPU 수보다 많은 인스턴스를 사용할 경우에는 각각의 인스턴스에 CPU가 배정 되는 시간이 느려지기 때문에 성능 저하로 이어질 가능성이 높다.
메모리의 크기, 운영체제의 비트 체계
64bit JVM은 32bit보다 30~40%의 Heap을 더 사용한다. 따라서 더 많은 메모리 할당이 필요하고, GC할 때 더 많은 시간이 걸린다. 하지만 32bit의 JVM은 아래와 같은 제약사항을 가진다.
G1 GC를 제외한 GC에서는 JVM Heap을 무한정 늘리면 Full GC 시간 증가로 인해 오히려 성능 병목이 될 수 있다. 32bit JVM을 사용하고 2-4GB 이하의 Heap 설정을 사용하는게 나을 수 있다. JVM의 Heap을 증가시키기 보다는 JVM의 인스턴스를 늘려 클러스터링이나 로드밸런서로 가용성을 확보하는 방법을 권장한다.
32bit의 운영체제에서 2GB의 메모리를 활용하는 JVM의 권장 Option
-Djava.awt.headless=true -server -Xmx1024m –Xms1024m -XX:NewSize=384m -XX:MaxNewSize=384m -XX:MaxPermSize=128m
Bash
복사
JVM의 Garbage Collector
JVM에서 어떤 GC를 사용할 것인지, 즉 GC 알고리즘에 따라 성능이 결정되기도 한다.
"그렇다면 어떤 컴퓨팅 환경과 JVM의 Garbage Collector에 따라서 전략이 달라질까?"
우리가 GC에 대해 이야기할 때, 우리 대부분은 그 개념을 알고 있으며 우리의 일상적인 프로그래밍에 그것을 사용하고 있다. 그럼에도 불구하고, 우리가 이해할 수 없는 일이 발생한다. JVM에 대한 가장 큰 오해 중 하나는 하나의 GC를 보유하고 있다는 점인데 그렇지 않다.
아래에서는 각각 고유한 장점과 단점이 있는 네개의 서로 다른 Garbage Collector를 살펴보도록 하겠다.
JVM의 다양한 Garbage Collector

http://blog.takipi.com/garbage-collectors-serial-vs-parallel-vs-cms-vs-the-g1-and-whats-new-in-java-8/
JDK 7부터 본격적으로 사용할 수 있는 G1 GC를 제외한, Oracle JVM에서 제공하는 모든 GC는 Generational GC이다. 즉 객체는 처음 생성되면 Eden(Young) 영역으로 들어간다. Minor GC가 일어나면 Eden, From 있는 객체 중 살아있는 객체를 To 영역으로 복사하고 나머지는 해제한다. 이러한 과정을 반복적으로 수행하다가 From, To 영역에서 오래된 객체들은 Old 영역으로 옮겨진다. 이러한 GC 알고리즘을 Copy & Scavenge 라고 하며 속도가 빠르다.
Old 영역에서 일어나는 ‘Major GC’는 Full GC 라고도 하는데, JVM에서 Full GC가 일어나면 모든 Thread가 멈추는 Stop the world 현상이 벌어진다. Full GC는 전체 객체들의 참조를 확인하면서 사용되지 않는 객체를 표시하여 삭제한다. 메모리 영역에 대한 compact가 필요하여 속도가 매우 느리다. 이렇게 활용되는 GC 알고리즘은 Mark & Compact 이라고 한다.
JVM을 튜닝한다는 의미는 Old 영역으로 넘어가는 객체의 수를 최소화하는 것과 Full GC의 실행 시간을 줄이는 노력이다.
Old 영역으로 넘어가는 객체의 수 최소화하기
즉, Eden 영역에서 객체가 처음 만들어지고, Survivor 영역을 오가다가, 끝까지 남아 있는 객체는 Old 영역으로 이동한다. 간혹 Eden 영역에서 만들어지다가 크기가 커져서 Old 영역으로 바로 넘어가는 객체도 있긴 하다. Old 영역의 GC는 New 영역의 GC에 비하여 상대적으로 시간이 오래 소요되기 때문에 Old 영역으로 이동하는 객체의 수를 줄이면 Full GC가 발생하는 빈도를 많이 줄일 수 있다. Old 영역으로 넘어가는 객체의 수를 줄인다는 말을 잘못 이해하면 객체를 마음대로 New 영역에만 남길 수 있다고 생각할 수 있지만, 그렇게는 할 수는 없다. 하지만 New 영역의 크기를 잘 조절함으로써 큰 효과를 볼 수는 있다.
Full GC 시간 줄이기
Full GC의 실행 시간은 상대적으로 Minor GC에 비하여 길다. 그래서 Full GC 실행에 시간이 오래 소요되면(1초 이상) 연계된 여러 부분에서 타임아웃이 발생할 수 있다. 그렇다고 Full GC 실행 시간을 줄이기 위해서 Old 영역의 크기를 줄이면 자칫 OutOfMemoryError가 발생하거나 Full GC 횟수가 늘어난다. 반대로 Old 영역의 크기를 늘리면 Full GC 횟수는 줄어들지만 실행 시간이 늘어난다. Old 영역의 크기를 적절하게 ‘잘’ 설정해야 한다.
이는 정답이 정해져있는 것이 아니라 시스템에 따라 지속적으로 모니터링하면서 수치를 정해야 한다는 뜻으로 지금까지의 내용을 JVM Options으로 예를 들면 아래와 같다.
JVM Options 예시
-Djava.awt.headless=true -server –Xms2048m -Xmx2048m -XX:NewSize=768m -XX:MaxNewSize=768m -XX:NewRatio=2 -XX:PermSize=128m -XX:MaxPermSize=256m -XX:USeParNewGC
Plain Text
복사
ParallelGC, UseConcMarkSweepGC와 같은 옵션을 볼 수 있는데 구체적으로 각기 다른 GC 알고리즘을 살펴보도록 하겠다.
The Serial GC
Serial GC는 가장 단순한 GC이지만 사용하지 않는 것을 추천한다. 싱글 쓰레드 환경을 위해 설계 되었고 아주 작은 Heap영역을 가진다. Full GC가 일어나는 동안 애플리케이션 전체가 대기해야하는 현상이 발생하기 때문에 서버 애플리케이션에 적당하지 않다.
The Parallel GC Threads
Java 8의 디폴트 GC인 Parallel GC는 문자 그대로 병렬로 GC한다. 메모리가 충분하고 CPU의 성능과 코어 개수가 많아 순간적으로 트래픽이 몰려도 일시 중단을 견딜 수 있고 GC에 의해 야기된 CPU 오버 헤드에 대해 최적화할 수 있는 애플리케이션에 가장 적합합니다.
•
XX:+UseParallelGC 옵션을 사용하여 Minor GC 에서 활성화 할 수 있다.
•
XX:+UseParallelOldGC 옵션을 사용하여 Major GC에서 활성화 할 수 있다.
The Concurrent Mark & Sweep GC
간단히 CMS GC라고도 하는데, Class Loader로 부터 최초의 객체 참조가 발생하는 Root를 시작으로 객체의 참조 상태를 관리한다.

http://d2.naver.com/helloworld/1329
초기 Initial Mark 단계에서는 Class Loader에서 가장 가까운 객체 중 살아 있는 객체만 찾는 것으로 끝낸다. 따라서, 멈추는 시간은 매우 짧다. 그리고 Concurrent Mark 단계에서는 방금 살아있다고 확인한 객체에서 참조하고 있는 객체들을 따라가면서 확인한다. 이 단계의 특징은 다른 스레드가 실행 중인 상태에서 동시에 진행된다는 것이다.

위의 화살표가 없는 객체와 같이 더이상 Root와 연관된 객체로 부터 참조되지 않는 객체를 Unreachable 객체라고 하며 GC의 대상으로 삼는다. CMS의 단점은 같은 성능을 위해 Parallel GC에 비해 더욱 많은 CPU 자원을 사용한다는 것인데 이와 같이 많은 CPU 리소스를 할당하려는 경우 메모리의 크기가 4GB 미만인 것으로 가정할 때 사용할 수 있는 GC 알고리즘이다.
만약 운영체제에서 JVM 인스턴스에 할당할 수 있는 메모리의 크기가 4GB보다 큰 경우에는 G1 GC 알고리즘을 사용할 수 있다. CMS는 애플리케이션의 Thread 정지 시간을 최소화 하여 응답시간 지연을 줄이고자 하는 웹 애플리케이션에 적당하다.
•
Major GC 실행시 Application Thread와 GC Thread가 동시에 수행된다.
•
XX:+UseConcMarkSweepGC 옵션을 사용하여 활성화 할 수 있다.
•
Minor GC에서 Parallel Collector를 활성화하기 위해서는 XX:+UseParNewGC 옵션을 사용해야 하며 XX:+UseParallelGC와 같이 사용해서는 안된다!
The G1(Garbage First) GC
G1 GC는 JDK 7u4 부터 도입되었으며 4GB이상의 더욱 큰 자원을 제공하고 장기적으로 CMS를 대체하기 위해 설계되었다. G1 GC를 이해하려면 지금까지의 Young 영역과 Old 영역에 대해서는 잊는 것이 좋다.
GC GC는 Generational 한 알고리즘과는 다르게 백그라운드의 멀티 쓰레드를 활용해 1MB에서 32MB까지의 수 많은 리젼으로 Heap을 분할한다.

http://d2.naver.com/helloworld/1329
G1 GC는 위와 같이 바둑판의 각 영역에 객체를 할당하고 GC를 실행한다. 그러다가, 해당 영역이 꽉 차면 다른 영역에서 객체를 할당하고 GC를 실행한다. 즉, 지금까지 설명한 Young의 세가지 영역에서 데이터가 Old 영역으로 이동하는 단계가 사라진 GC 방식이라고 이해하면 된다.
G1 GC의 가장 큰 장점은 성능이다. G1은 지연 시간을 줄이기 위해서 지금까지 설명한 어떤 GC 방식보다도 빠르다.
하지만 이와 같이 4GB 이상의 큰 Heap을 가지는 것은 요즘과 같이 마이크로 서비스 아키텍쳐에서는 논쟁 거리가 될만하다. 지난 몇 년동안 많은 개발자들이 거대한 시스템을 작은 마이크로 단위로 옮기는 노력을 해왔기 때문이다.
이는 다양한 애플리케이션을 서로 격리하고 효율적인 배포 프로세스를 통해 거대한 애플리케이션 클래스를 메모리에 로드하는데 소요되는 비용을 절감하는 등 많은 요인을 포함하고 있다. 이는 애플리케이션을 동일한 물리적 머신에 배포할 수 있도록 하는 Docker와 같은 컨테이너 기술에 의해 가속화 되어 왔다.
Class Unloading에 대한 이슈
Hot Deploy(Hot Swapping)를 많이 할 경우 Java 7의 G1 GC에서는 Perm Generation 영역에 문제가 발생할 수 있다.
•
JDK 7의 G1 GC는 Class Unloading을 Full GC가 발생했을 시에만 수행하게 된다.
•
이 문제는 JDK 8u40 버전에서 Perm Generation을 없애고 Metaspace 방식으로 바꾼 후에 해결되었다.
•
XX:+UseLargePagesInMetaspace
JDK 8에서는 Perm 영역이 아니라 Metaspace에 클래스 정보가 올라가는데 이때 그 영역이 크면 GC 시간이 오래 걸릴 수 있는데 이럴 때는 Metaspace에 Large Page를 사용하여 접근하도록 JVM 옵션을 주면 대부분 문제가 해결될 수 있다는 것
JVM Options 예시
-Djava.awt.headless=true -Dfile.encoding=UTF-8 -server -Xms2048m -Xmx2048m -XX:MaxMetaspaceSize=512m -XX:+UseG1GC -XX:+DisableExplicitGC -XX:+UseStringDeduplication
Bash
복사
Java 9의 디폴트 GC는 G1이다
최근에 Java 9 출시 소식이 있었다. JDK 9에 포함된 다양한 Features 중 32-bit, 64bit 서버 환경에서 G1을 디폴트 Garbage Collector로 변경한 내용이 있다. 더불어 CMS GC는 JDK 9에서 Deprecated 되었다.
Make G1 the Default Garbage Collector
많은 성능 개선 사항이 JDK 8의 G1과 업데이트 릴리스에 따라 이루어졌으며, 추가 개선 사항이 JDK 9에 추가되었다. 예를 들면 JEP156 이슈는 G1을 완전한 품질의 Garbage Collector로 만들 수 있게 해줬다.
이러한 Garbage Collector에 대한 변화는 Parallel GC와 같이 처리량을 극대화하는 것보다 GC의 지연 시간을 제한하는 것이 더 중요하다는 가정 하에 이루어졌다. 만약 이 가정이 잘못되었다면 이 변화는 재고해야 할 필요가 있을 수 있다.
G1은 튜닝하기 쉽게 설계되었다
Stop The World로 인한 지연 시간을 기본으로 하는 튜닝
-server -Xmx32G -XX:MaxGCPauseMillis=100
Bash
복사
-XX:MaxGCPauseMillis의 디폴트 값은 250ms 이다.
어떤 GC 알고리즘을 선택해야 할까?
우리는 다양한 GC 알고리즘을 살펴보았지만 중요한 것은 모든 서비스에 완벽하게 맞아 떨어지는 GC 알고리즘은 없다는 것이다. 각 애플리케이션의 특정 동작에 따라 처리량을 극대화하거나 지연 시간을 줄이는 옵션을 따져 적합한 GC를 사용하도록 하자.
Java 9에서도 여전히 ParallelGC를 사용할 수 있기 때문이다.
JVM 튜닝 꼭 해야할까?
JVM 튜닝은 가장 마지막에 고려하는 것이 좋다.
"JVM 튜닝을 하기전에 스스로에게 3번정도 꼭 다시 물어보자."
그 이유는 대게의 문제는 JVM 튜닝이 필요한 것이 아니라 애플리케이션 내부에 이슈가 있는 경우가 많기 때문이다. 애플리케이션을 구동하는 운영체제에 메모리가 해제되지 않는 등의 이상 징후가 생긴다면, 먼저 애플리케이션에서 과도하게 많은 메모리를 차지하는 객체를 추적할 필요가 있다.
특히 웹 애플리케이션과 같은 멀티 쓰레드 환경에서는 한 자원에 여러 쓰레드가 동시에 접근하면서 메모리 참조에 이상이 생기는 경우가 있다.
이 의미는 Garbage 객체가 누수되어 시스템에 좋지 않은 영향을 미친다는 것이다. 가장 많이 하는 실수는 메모리를 이용하는 클래스를 구현하면서 클래스 내부의 HashMap을 잘못 사용하는 경우이다. HashMap의 put(), get()를 사용할 때에는 동기화 기법을 통해 Thread Safe하게 코드를 작성하거나 ConcurrentHashMap 를 사용하는 것을 추천한다.
이어서 메모리 참조에 이상이 생긴 객체들을 효과적으로 찾는 다양한 기법을 알아보도록 하자.
GC 모니터링
GC 로그를 위한 JVM Options
XX:-PrintGC -XX:-PrintGCDetails -XX:-PrintGCTimeStamps -XX:-TraceClassUnloading -XX:-TraceClassLoading
Bash
복사
스레드 덤프 획득
스레드 덤프를 획득하는 방범은 여러 가지가 있지만 기본적으로 JVM의 옵션을 통해 Out Of Memory 에러 발생시 아래와 같이 쓰레드 덤프를 획득할 수 있다.
-XX:-HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=./java_pid<pid>.hprof
Bash
복사
애플리케이션의 현재 프로세스를 확인하고 실시간으로 쓰레드 덤프를 얻기 위해서는 획득할 당시의 스레드 상태만 알 수 있기 때문에 스레드의 상태 변화를 확인하려면 5초 정도의 간격으로 5 ~ 10회 정도 획득하는 것이 좋다.
$ jps -v
8352 GradleMain -Dorg.gradle.appname=gradle
8372 GradleDaemon -XX:MaxPermSize=256m -XX:+HeapDumpOnOutOfMemoryError -Xmx1024m -Dfile.encoding=UTF-8 -Duser.country=US -Duser.language=en -Duser.variant
8409 Jps -Dapplication.home=/Library/Java/JavaVirtualMachines/jdk1.8.0_102.jdk/Contents/Home -Xms8m
...
$ jstack :PID
...
$ kill -3 :PID
...
Bash
복사
jstat 명령을 통한 GC 모니터링
현재 JVM의 메모리 상태를 확인할 수 있다.
$JAVA_HOME/bin/jstat
Bash
복사
Memory Analyzer(MAT)
이클립스를 사용한다면 MAT 플러그인도 도움이 된다. MAT은 hprof 파일을 분석해서 메모리 분석, 통계를 내는 기능을 제공한다.
정리하며
지금까지 Java 시스템 운영 중 알아두면 쓸데있는 지식들을 살펴보았습니다. 대용량의 웹 애플리케이션을 운영 하다보면 다양한 문제에 노출되기 쉬운데 여러 각도에서 자신의 시스템을 바라볼 수 있다면 더욱 견고한 시스템을 만들 수 있을 것이라고 생각합니다. 아래는 이 글을 작성하면서 참고한 문서들인데 도움이 되었으면 합니다 :)